Was ist Web Scraping und wie funktioniert es in der digitalen Welt?
Daten(Data) und Informationen sind zwei Begriffe, die oft synonym verwendet werden, aber es gibt einen bemerkenswerten Unterschied zwischen ihnen. Beispielsweise beziehen sich Daten auf Informationsbits, aber nicht auf Informationen selbst. Andererseits sind Informationen(Information) eine Menge von Daten, die sinnvoll verarbeitet werden. Mit den überwältigenden Daten, die im Internet verfügbar sind, werden verschiedene Ansätze wie Web Scraping , Web Harvesting oder Web Data Extraction verwendet, um umsetzbare und bahnbrechende Erkenntnisse über die Internetnutzung(Internet) zu gewinnen . Aber was genau bedeuten sie in der Online-Welt. Lass uns mal sehen!
Wie funktioniert Web Scraping?
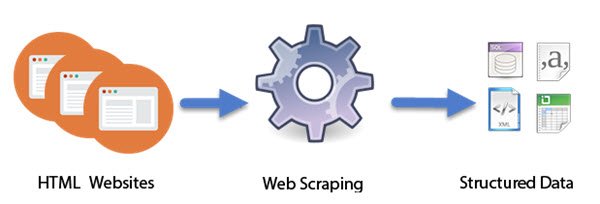
Computerprogramme(Computer) , die als intelligente(Intelligent) Bots konzipiert sind, erledigen die Arbeit des Web Scraping . Im Gegensatz zum Screen Scraping, bei dem nur die auf dem Bildschirm angezeigten Pixel kopiert werden, extrahiert das Web Scraping den zugrunde liegenden HTML -Code und damit die in einer Datenbank gespeicherten Daten. Der Ansatz ist sehr beliebt geworden. Tatsächlich wird es als eine der wesentlichen Fähigkeiten angesehen, die man sich in der heutigen digitalen Welt aneignen muss. Es hat einige großartige Anwendungen beim Kompilieren großer Datensätze, die für Techniken wie
- Big-Data-Analyse(Big Data Analytics)
- Maschinelles Lernen
- Künstliche Intelligenz(Artificial Intelligence)
Mit der schnellen Ausbreitung digitaler Informationen ist der Zugriff auf Big Data über Web Scraping oder Web Data Extraction viel einfacher geworden. Allerdings kann Web Scraping für digitale Unternehmen eingesetzt werden , die sich sowohl in legitimen(Legitimate) als auch in illegitimen Fällen auf das Sammeln von Daten verlassen. Ersteres enthält Beispiele für wohlwollendes Web Scraping(Benevolent Web Scraping Examples) , während letzteres Beispiele für bösartiges Web Scraping(Malicious Web Scraping) enthält .
Beispiele für wohlwollendes Web Scraping
- Suchmaschinen(Search) -Bots, die eine Website crawlen und deren Inhalt analysieren, um basierend auf bestimmten Ergebnissen einen Rang zuzuweisen, wie Google .
- Preisvergleichsseiten(Price) , die Bots einsetzen, um Preise von Produkten automatisch abzurufen
- Marktforschungsunternehmen(Market) verwenden Scraper, um Daten aus sozialen Medien zu extrahieren (z. B. für Stimmungsanalysen, persönliche Vorlieben usw.).
Beispiele für bösartiges Web Scraping
Web Scraping für illegale Zwecke kann schwere finanzielle Verluste verursachen, wenn Daten ohne die Erlaubnis der Website-Eigentümer extrahiert werden. Die beiden häufigsten Anwendungsfälle von Malicious Web Scraping sind Price Scraping und Content-Diebstahl.
- Price Scraping – Scraper- Bots inspizieren konkurrierende Geschäftsdatenbanken, um auf Preisinformationen zuzugreifen, Konkurrenten zu unterbieten und den Umsatz zu steigern.
- Inhaltsdiebstahl(Content Theft) – Diese illegitime Aktivität umfasst den groß angelegten Diebstahl von Inhalten von einer Zielwebsite. Typische Ziele sind hauptsächlich Online-Produktkataloge und Websites, die auf digitale Inhalte angewiesen sind, um das Geschäft voranzutreiben.
Hoffe das hilft!

About the author
Ich bin ein Softwareentwickler mit über 10 Jahren Erfahrung auf den Plattformen Windows 11 und 10. Mein Fokus lag auf der Entwicklung und Wartung hochwertiger Software für Windows 7 und Windows 8. Ich habe auch an einer Vielzahl anderer Projekte gearbeitet, einschließlich, aber nicht beschränkt auf Chrome, Firefox, Xbox One und Dateien.
Related posts
Keine Internetverbindung, wird aber als mit dem Web verbunden angezeigt
Was ist Bitcoin, die digitale Währung
Was mit Ihren Online-Konten passiert, wenn Sie sterben: Digital Assets Management
Was ist Dark Web oder Deep Web? Zugriff und Vorsichtsmaßnahmen.
Vorteile der Einnahme von Digital Detox und wie man vorgeht
Surfer vs. Websitebesitzer vs. Werbeblocker vs. Anti-Werbeblocker-Krieg
Sucht nach Internet und sozialen Netzwerken
Beste kostenlose Internet Security Suite Software für Windows 11/10 PC
Internet funktioniert nach einem Update auf Windows 11/10 nicht
Verbindung zum Internet nicht möglich? Probieren Sie das Complete Internet Repair Tool aus
Wie können Sie die Einstellungen Ihres WLAN-Routers ändern oder ändern?
Cyberkriminalität und ihre Klassifizierung - organisiert und unorganisiert
So fügen Sie eine vertrauenswürdige Site in Windows 11/10 hinzu
Group Speed Dial für Firefox: Wichtige Internetseiten immer zur Hand
Brute-Force-Angriffe – Definition und Prävention
So verwenden Sie eine gemeinsam genutzte Internetverbindung zu Hause
Screamer Radio ist eine anständige Internetradio-App für Windows-PCs
Lebensende des Internet Explorers; Was bedeutet es für Unternehmen?
Artikel zur Internetsicherheit und Tipps für Windows-Benutzer
Wofür stehen häufige HTTP-Statuscode-Fehler?